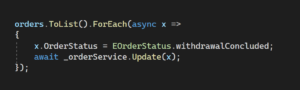
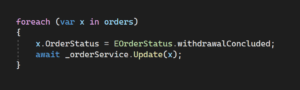
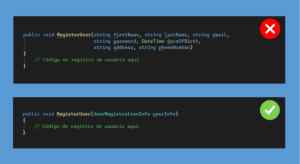
Olá, Devs!!! Primeiramente, bem-vindos ao nosso guia sobre os Comandos Git. Caso esteja buscando dominar o controle de versão e estar totalmente atualizado, saiba que está no lugar certo. De fato, o Git não é apenas uma ferramenta – representa uma revolução na forma como gerenciamos e colaboramos em projetos de código. Neste post, pretendo abordar os comandos essenciais do Git, com o objetivo de ajudar você a navegar com confiança neste universo.
Afinal, sei que você tem interesse em mergulhar no mundo do GitHub e do Git, não é mesmo? Bem, você está no lugar certo. De fato, o Git é uma das ferramentas de controle de versão mais populares e, por boas razões. Ademais, para enriquecer ainda mais a experiência, temos o GitHub, uma plataforma que não apenas permite hospedar, mas também colaborar e compartilhar nosso código-fonte com o mundo. Então, que tal começarmos do início?
1. Configurando tudo
Primeiramente, antes de fazermos qualquer coisa, precisamos nos apresentar para o Git. Mas por quê? Simplesmente porque, cada vez que fazemos uma alteração, o Git quer saber quem somos. Então, diga ao Git o seu nome usando:
git config –global user.name “Seu Nome”
Ah, e não se esqueça do seu e-mail. Afinal, ele é importante, principalmente se você planeja colaborar em projetos públicos. Use:
git config –global user.email “seu@email.com”
2. Dando os primeiros passos
Ok, agora que nos apresentamos, o que fazemos a seguir? Se você estiver começando um novo projeto, você vai querer inicializar um repositório Git. Isso é bem simples, basta usar:
git init
Por outro lado, se você encontrou um projeto interessante no GitHub e quer uma cópia dele para trabalhar localmente, você vai precisar “cloná-lo”. E adivinhe só? É super fácil:
git clone URL_DO_REPOSITÓRIO
3. Lidando com alterações
Agora, aqui está a parte divertida. Depois de trabalhar um pouco, você notará que fez algumas alterações. E é aqui que a mágica acontece. Primeiro, sempre verifique o status do seu repositório. Acredite, isso se tornará um hábito!
git status
Se você modificou ou adicionou alguns arquivos, é hora de prepará-los para um “commit”. Mas o que é um commit? Pense nisso como uma fotografia de como as coisas estão no momento. Então, adicione seus arquivos:
git add NOME_DO_ARQUIVO
Ou, se você estiver se sentindo aventureiro e quiser adicionar todas as suas alterações:
git add .
Agora, faça um “commit” com uma mensagem significativa sobre o que você fez:
git commit -m “Mensagem do commit”
4. Navegando entre branchs
Talvez você já tenha ouvido falar sobre “branchs” ou ramos. Elas são vias paralelas que permitem testar novidades sem alterar o curso original do seu projeto. Para listar suas branchs:
git branch
E se você quiser tentar algo novo? Crie uma branch:
git branch NOME_DA_BRANCH
E então mude para ela:
git checkout NOME_DA_BRANCH
Ah, e quando estiver pronto para juntar essa branch de volta ao principal? Use:
git merge NOME_DA_BRANCH
5. Sincronizando com o mundo
Então, depois de fazer todo esse trabalho, você vai querer compartilhá-lo com o mundo, certo? Para trazer as últimas alterações do GitHub:
git pull origin BRANCH
E para mostrar ao mundo suas incríveis alterações:
git push origin BRANCH
6. Conectando com repositórios remotos
Depois de dominar os básicos, certamente você vai querer conectar seu repositório local a um remoto, com o intuito de dar a você o poder de colaborar com outros desenvolvedores. Nesse sentido, esse comando une seu espaço de trabalho local a um repositório online, estabelecendo um link essencial para o trabalho colaborativo.
git remote add NOME_REMOTO URL_DO_REPOSITÓRIO
Ah, e se você estiver curioso sobre quais repositórios remotos estão conectados ao seu local, o comando abaixo vai listar todos eles para você, tornando fácil ver e gerenciar suas conexões.
git remote -v
7. Explorando o histórico de fazendo ajustes
Agora, uma das maiores vantagens do Git é poder revisitar e entender o histórico do seu projeto e ter um registro detalhado de cada commit feito, permitindo que você explore as mudanças e entenda a evolução do seu projeto:
git log
E se quiser ver as alterações específicas de cada arquivo?
git diff
8. Desfazendo e guardando mudanças
A vida é cheia de erros e no desenvolvimento, isso não é diferente. Se você fez uma mudança que não era o que queria e quer descartar as alterações feitas no arquivo especificado, trazendo de volta a versão do último commit então…
git checkout — NOME_DO_ARQUIVO
Talvez, você só queira desfazer a adição de um arquivo à área de staging. Nesse caso, o comando abaixo é seu aliado, removendo o arquivo da área de staging, mas mantendo suas alterações.
git reset HEAD NOME_DO_ARQUIVO
E para aqueles commits que, bem, não deveriam ter acontecido?
git revert HASH_DO_COMMIT
Eventualmente, você pode se encontrar envolvido em uma atividade, mas de repente, necessita alternar rapidamente para uma tarefa diferente, preservando suas alterações atuais. Neste contexto o comando abaixo surge como um recurso indispensável, permitindo que você armazene modificações temporariamente, resultando em um diretório limpo e pronto para receber novos trabalhos.
git stash
E quando estiver pronto para retomar e trazer tudo de volta?
git stash pop
Por último, para manter tudo limpo, organizado e remover todos aqueles arquivos não rastreados e pastas, deixando seu repositório em estado de brilho.
git clean
Cobrimos bastante coisa referente a Comandos Git heim?! E olhe, isso é apenas a ponta do iceberg. O Git é uma ferramenta poderosa e quanto mais você o usa, mais truques você aprenderá e se alguma vez se encontrar em apuros, saiba que quase sempre há uma maneira de corrigir as coisas.
Boa sorte na sua jornada Git e GitHub!!!